혼공학습단 7기 혼자 공부하는 머신러닝+딥러닝 3주차 미션
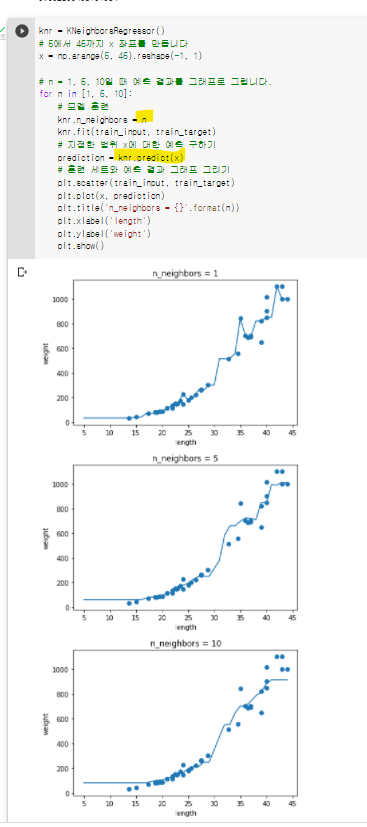
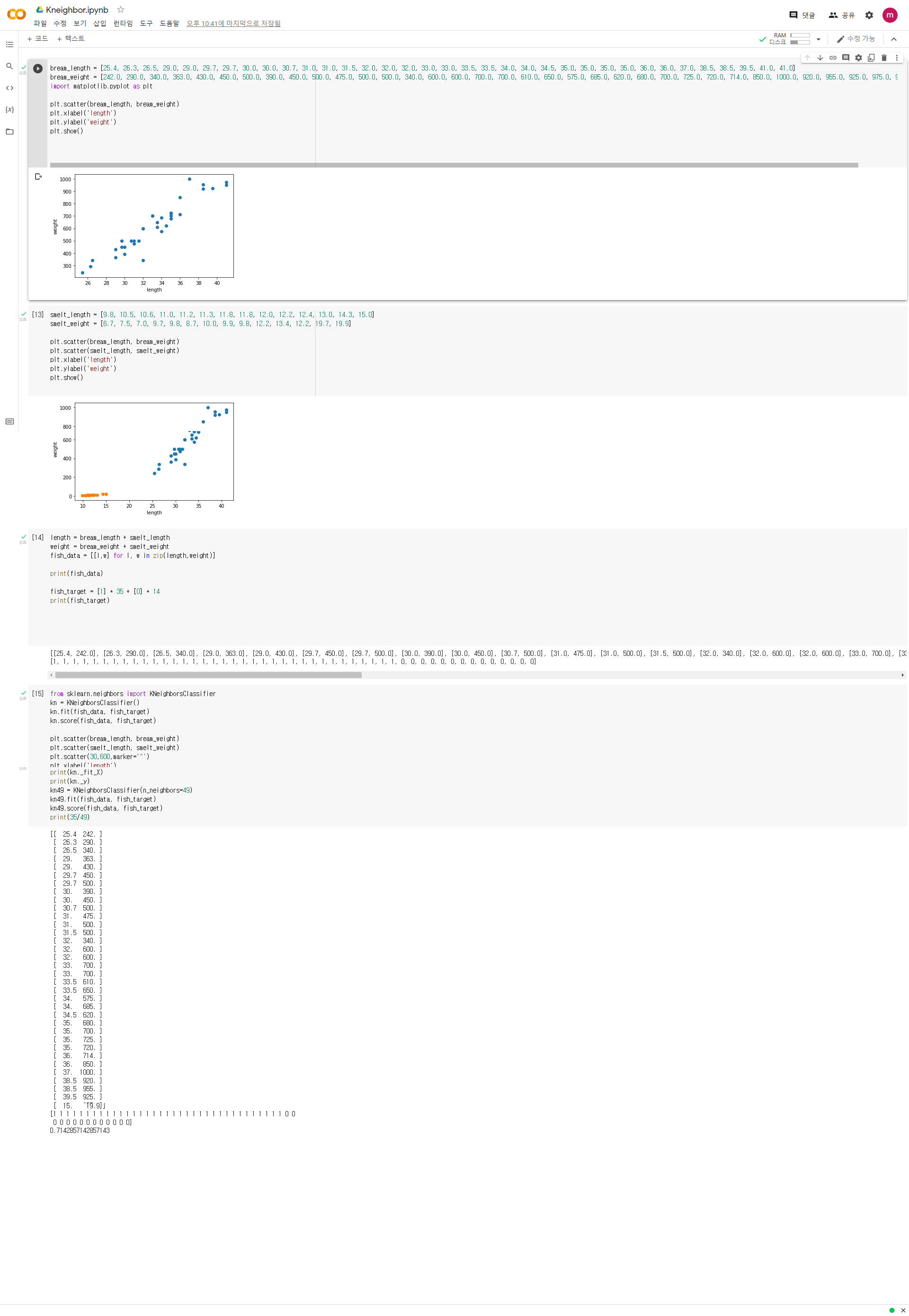
3주차 미션 범위 : Chapter 04 미션 : Chapter 04(04-1) 2번 문제 풀고, 풀이 과정 설명하기 선택미션 : Chapter 04(04-2) 과대적합/과소적합 손코딩 코랩화면 캡쳐하기 미션 1. Chapter 04(04-1) 2번 문제 풀고, 풀이 과정 설명하기 문제 - 로지스틱 회귀가 이진 분류에서 확률을 출력하기 위해 사용하는 함수는 무엇인가요? 1) 시그모이드 함수 * 풀이 설명 - 로지스틱 회귀 : 선형 방정식을 사용한 분류 알고리즘 a,b,c,d,e는 가중치 혹은 계수이다. 여기서 결과값인 z값을 어떤 값이든 가능하지만 확률이 되게 하기 위해 0 ~ 1(0~100%)의 값이 되어 합니다. 이를 위해 시그모이드 함수(로지스틱 함수)를 사용합니다. -> 이름부터가 로지스틱 회귀를 위한 함수이죠? - 시그모이드 함수 : S자형 곡선 또는 시그모이드 곡선을 갖는 수학 함수로 수식과 그래프는 아래와 같습니다. --> 뭔가 이전에 2주차 미션때 했던 과대 과소적합의 그래프를 살짝 비슷하게 닮았군요. 30정도 학습시키면 이와 비슷한 모양이 나왔었죠.. 40이 넘어가면서 직선화 되었는데.. 그러면 이 그래프도 직선과 비슷하게? 보이게 할 수 있을지... 확인해보죠 p.184를 보시면 간단하게 구현한 소스코드가 나오는데... z = np.arange( -5 , 5 , 0.1 ) 의 범위를 바꿔보겠습니다. (-10,10,0.1)로 바꾸니 경사가 급격해졌습니다. 그러면 (-1,1,0.1)로 바꿔보니 일차 방정식의 형태로 나타났습니다. 저기 저 경사부분을 완만하게 늘리면 y = a 꼴로 나오지 않을까 하여 여러가지 값을 바꾸며 확인해봤지만 아래와 같이 직선의 방정식 형태로만 나타났습니다. 이유는 분류를 하기 위한 모델이기 때문인 것 같습니다. (수식이 그렇게 나올 수 없기 때문이겠죠?) 선택미션 1. Chapter 04(04-2) 과대적합/과소적합 손코딩 코랩화면 캡쳐하기 빨간색으로 표시한 부분이 과대적합/과소적합 부분이다. 300번을